Hadoop クラスタ内の大きなデータは、主に MapReduce パラダイムを使用して分析されます。通常、この目的のために特定のJavaジョブが作成されますが、Python やシェルスクリプトなど、さまざまなプログラミング言語が使用されることがあります。そのような場合、Hadoop Streaming は IoT platform インテグレータが必要とする機能です。
次に、Hue(HadoopのWebインターフェイス)を使用して Python ベースの MapReduce ジョブを作成する方法と、具体的には Job Designer と Oozie Editor ツールの2つの方法を示します。以前は、マッパーやデューサーのための Python コードの作成やアップロード、またはいくつかのテストデータファイルのアップロードなど、いくつかの設定手順を実行する必要がありました。
セットアップ¶
重要な注意: インテグレータとして、チュートリアルに表示されている 'admin' ユーザを自分のユーザに置き換えてください。
Python コード¶
いくつかの Python スクリプトを提供する必要があります。一つはマッパー・ロジックを実装し、もう一つはリデューサー・ロジックを実装するものです。これらの2つのファイルは、後で実行されるときに MapReduce ジョブの引数として渡されます。デモストレーションの目的で、Java ベースの WordCount アプリケーションを模倣する次のコードが使用されます :
$ cat mapper.py
#!/usr/bin/env python
import sys
# input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
#
# tab-delimited; the trivial word count is 1
print '%s\t%s' % (word, 1)
$ cat reducer.py
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)上記2つのローカルファイルは、Hue のファイルブラウザを使用して HDFS ユーザスペースのどこかにアップロードする必要があります :

データ¶
Hue の File Browser を使用して、hdfs:///user/admin/demo-mr-python/input に任意の非バイナリローカルファイルをアップロードしてください :
$ cat data.txt
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
ジョブデザイナでの Hadoop ストリーミング¶
これは、Python ベースの MapReduce ジョブを作成する最も簡単な方法です。まず、Hue インターフェースにアクセスし、Job Designer ツールを起動します。ストリーミングタイプの新しいアクションを追加します :
次に、名前、説明、およびマッパーとリデューサーのコードを実装する Python スクリプトを指定してフォームに記入します。これらのファイルの場所がアーカイブオプションとして追加されていることに注意してください。最後に、入出力ジョブのプロパティを指定します :

Hadoop ではいつものように、出力ディレクトリはジョブ実行の前に存在してはいけません。
新しいストリーミング・アクションがアクションのリストに追加され、今すぐ実行できます。実行中に、進行状況を示すOozie Dashboard が開きます。Job Browser を使用して進行状況を追跡することもできます :
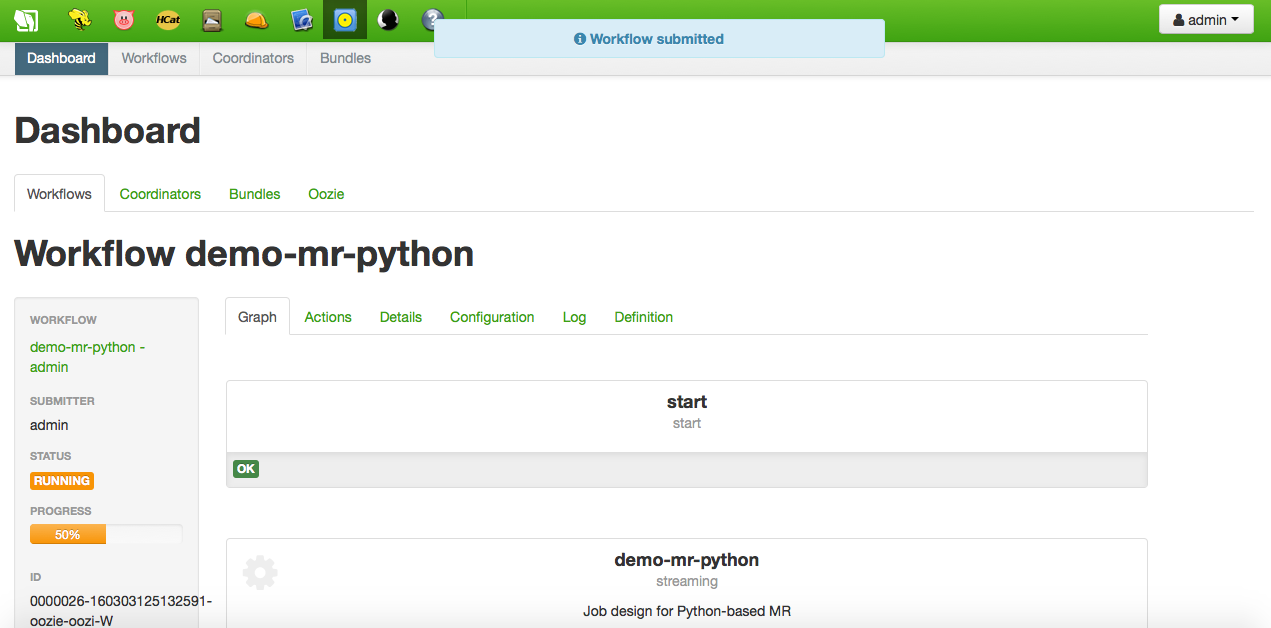

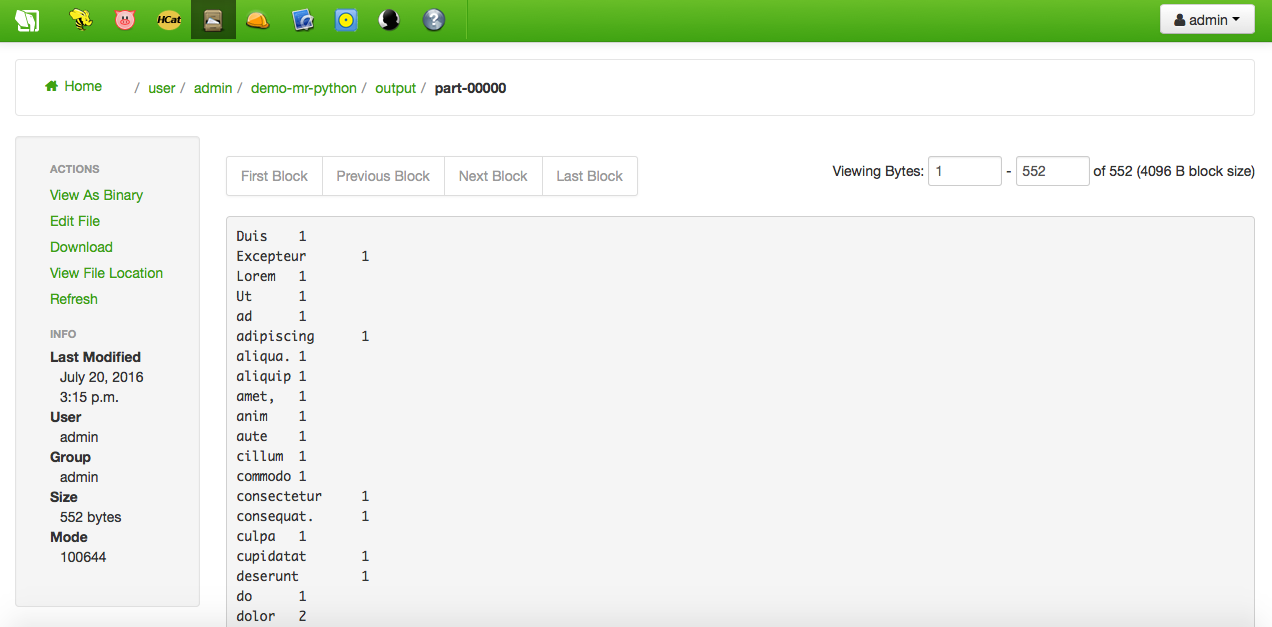
正常に終了すると、ジョブによって作成された出力ディレクトリを参照できます。part-0000 ファイルの内容だけでなく、データファイルの単語数も次のようになります :
Oozie Editor での Hadoop ストリーミング¶
これは、Python ベースの MapReduce ジョブを作成する高度な方法です。Oozie Editor を使用すると、チェーンジョブの複雑な Oozie ワークフローを作成することができます。つまり、ジョブの出力をワークフローの次の入力に接続することができます。ジョブにはもちろん MapReduce アプリケーションを使用できますが、Hive や Pig のクエリ、シェルスクリプトや標準の Java アプリケーションなどがあります。ワークフローを定義すると、これを実行したり、将来の実行のためにスケジュールすることができます。
まず、Oozieエディタを開き、ワークフロー・タブを選択します。そこで、Create ボタンをクリックして、新しい Oozieワークフローを作成します :

まず、ワークフローの名前を選択し、説明を入力します。次に、ワークフローエディタが開きます :
今からワークフローにノードを追加します。この簡単なチュートリアルでは、ストリーミングタイプのノードが1つだけ追加されます。上のオプションから、エディタの開始ノードと終了ノードの間のスロットにドラッグ&ドロップするだけです。一度ドロップすると、ノードエディタが開きます :
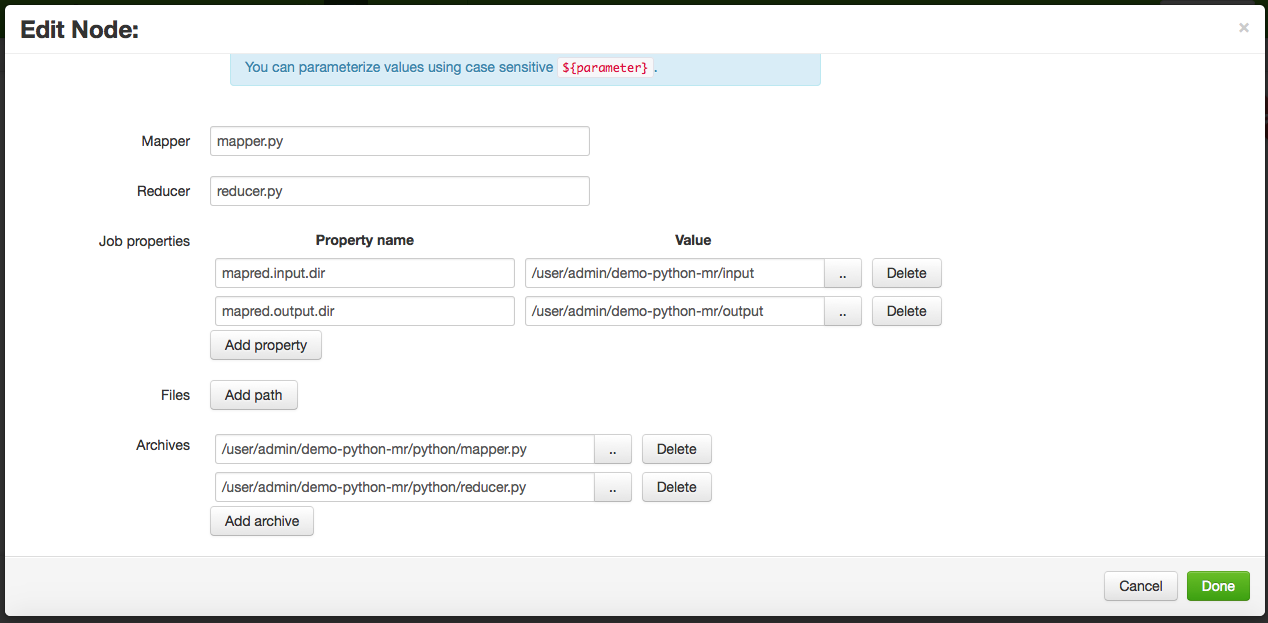
ご覧のとおり、ストリーミングノードの設定は、ジョブデザイナで使用されているものと同じです(前のセクションを参照)。ストリーミングの後にノードを追加することもできますが、このチュートリアルではノードは必要ありません。したがって、ワークフローが設定されると、ワークフローは実行者またはスケジュールされた状態になります。
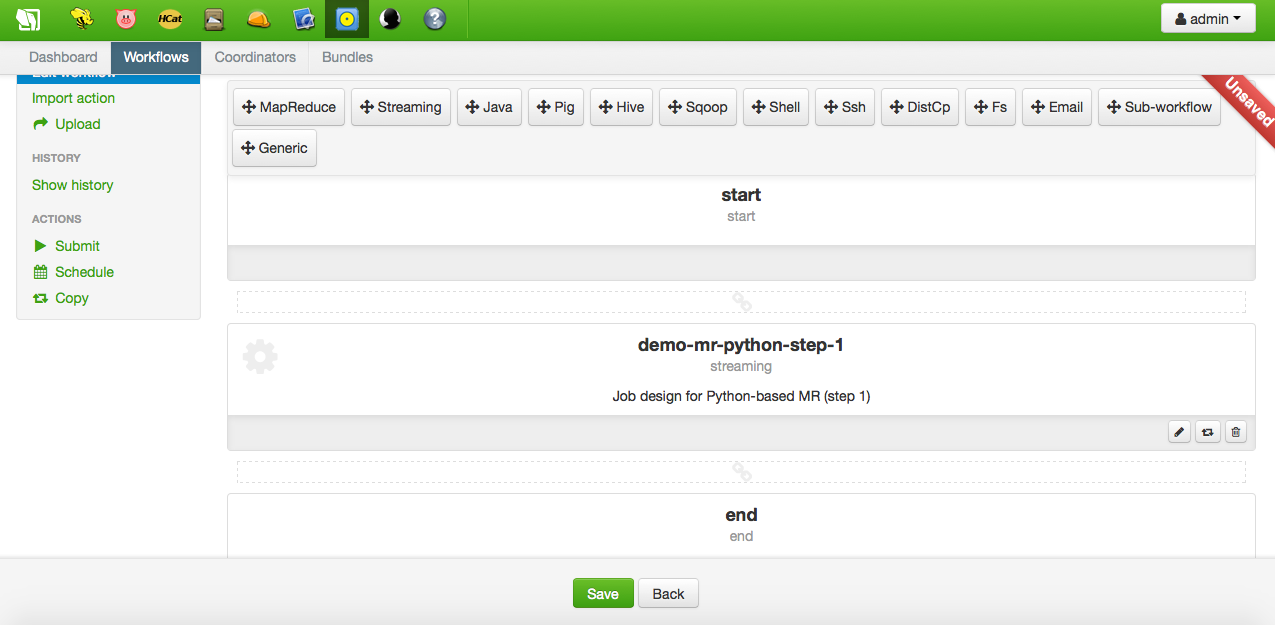
実行後、出力ディレクトリとその part-0000 ファイルはいつものように閲覧できます :
